Feature Engineering
데이터가 수집되고 [데이터셋 생성] 버튼을 클릭하면 TML 서비스가 자동으로 수집된 데이터의 기술 통계 자료를 분석합니다.
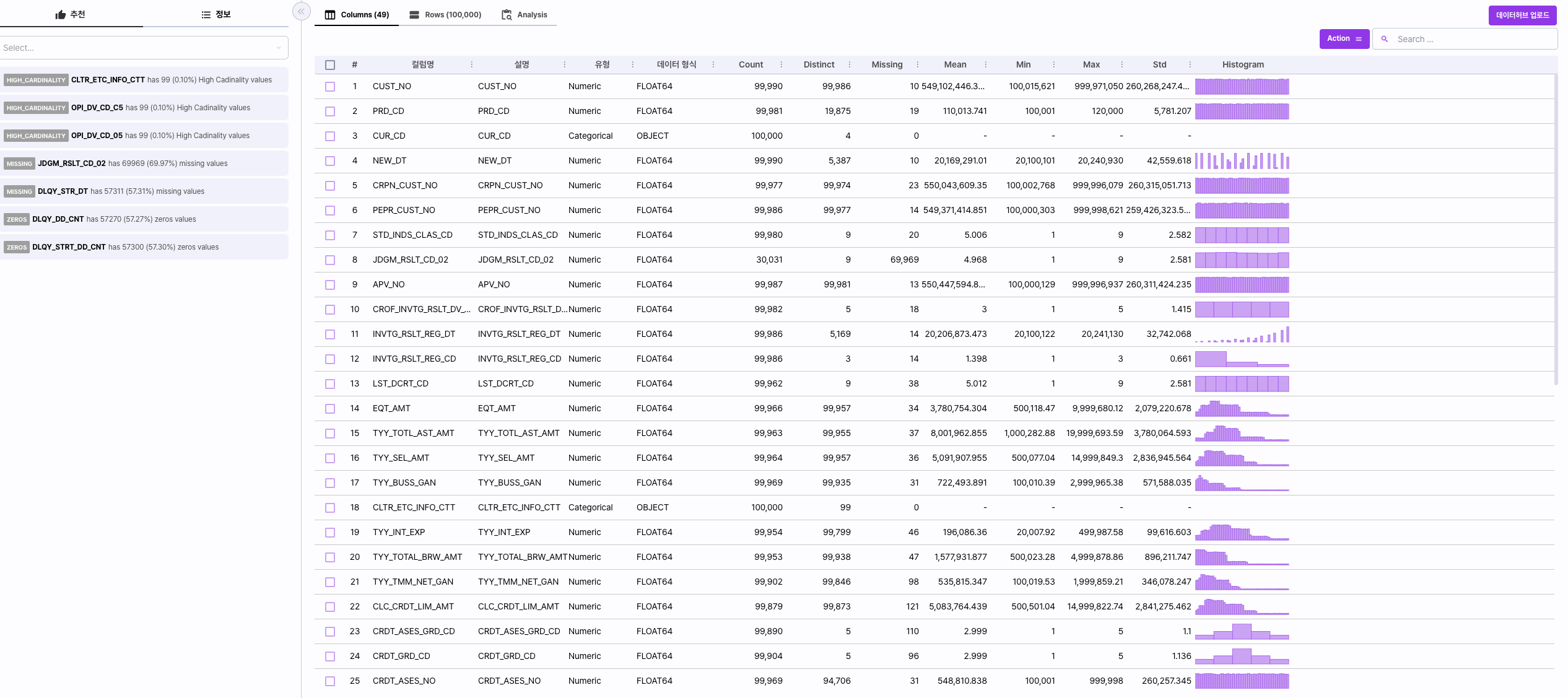
특징 분석 탭을 통해 자동으로 분석한 기술 통계 자료를 영역별로 확인할 수 있습니다.
| 필드명 | 설명 |
|---|---|
| 개요 | 데이터의 전반적인 정보를 표시합니다. |
| 유형 | 데이터를 구성하고 있는 컬럼들의 타입을 표시합니다. |
| 추천 | 데이터를 자동으로 분석해 전처리가 필요한 사항을 추천합니다. |
| 특징 분석 | Columns, Rows, Analysis 탭으로 구성되어 있습니다. - Columns: 컬럼 별 형식과 수, 최대 최소값과 같은 통계자료를 표시합니다. - Rows: 실제 Row 별 데이터를 조회할 수 있습니다. - Analysis: 데이터의 시각화 분석 자료를 제공합니다. |
| 오른쪽 사이드바 | 선택한 컬럼의 기술 통계 자료를 표시합니다. |
Data Recommandation
추천 화면은 TML 서비스가 자동으로 데이터셋에서 전처리가 필요한 컬럼과 처리 방법을 추천합니다.
추천 화면에서 제공하는 정보는 다음과 같습니다.
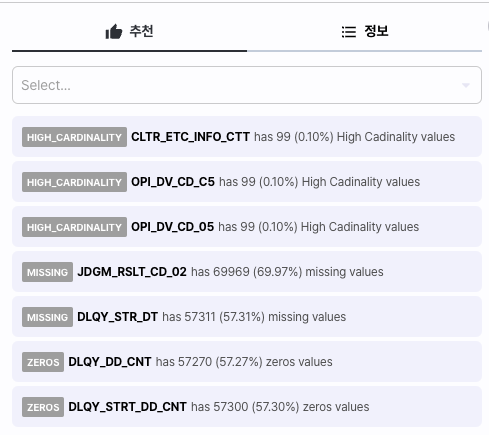
추천사항의 구성은 다음과 같습니다.
- 구분: 추천 사항
- 대상컬럼: 컬럼명
- 내용: 컬럼이 추천된 이유
추천 사항의 종류는 다음과 같습니다.
| 추천 사항 | 설명 |
|---|---|
| SKEWED | 데이터가 불균형하게 구성 |
| UNSUPPORTED | 지원하지 않는 데이터 |
| MISSING | 누락된 데이터가 포함되어 있음 |
| CONSTANT | 데이터가 단일값으로 구성 |
| ZEROS | 데이터가 0으로만 구성 |
| REJECTED | CONSTANT, ZEROS가 존재해 해당 컬럼을 사용 불가 |
| HIGH_CARDINALITY | 매우 드물거나, 고유한 값들로 이뤄진 컬럼 |
추천 사항을 참고하여 해당 컬럼을 제거할지, 별도의 전처리 기술을 적용할지 판단할 수 있습니다.
Data Characteristic
특징 분석 화면에서 컬럼을 선택하면 오른쪽 사이드바에 다음과 같은 정보가 표시됩니다.
화면에서 CRU_CD컬럼을 선택 합니다.
| 필드명 | 설명 |
|---|---|
| Distinct | 선택한 컬럼에서 중복되지 않은 로우의 수를 표시합니다. |
| Distinct(%) | 선택한 컬럼에서 전체 로우에 중복되지 않은 로우가 차지하는 비율을 표시합니다. |
| Unique Column | 선택한 컬럼의 데이터가 고유한지에 대한 여부를 표시합니다. |
| Unique | 누락된 값을 제외하고 고유한 값의 수를 표시합니다. |
| Unique (%) | 누락된 값을 제외하고 고유한 값의 비율을 표시합니다. |
| Variable Types | 데이터의 타입을 표시합니다. |
| Hashable | 선택한 데이터가 해쉬화 되어 있는지를 표시합니다. |
| Ordering | 선택한 데이터가 정렬되어 있는지를 표시합니다. |
| Missing | 해당 데이터에서 누락된 값의 수를 표시합니다. |
| N | 누락된 값을 포함해 전체 로우의 수를 표시합니다. |
| Missing(%) | 해당 컬럼에 있는 누락 데이터의 비율을 표시합니다. |
| Count | 해당 컬럼에서 누락 값을 제외한 데이터 수를 표시합니다. |
| Memory_size | 해당 컬럼이 차지하는 메모리 사이즈를 표시합니다. |
| Column name | 컬럼명을 표시합니다. |
| DataType | 데이터 유형을 표시합니다. |
Chart
Analysis 탭에서 [컬럼 선택] 버튼을 선택하면 수집한 데이터로 분석 가능한 차트 정보를 선택할 수 있습니다.
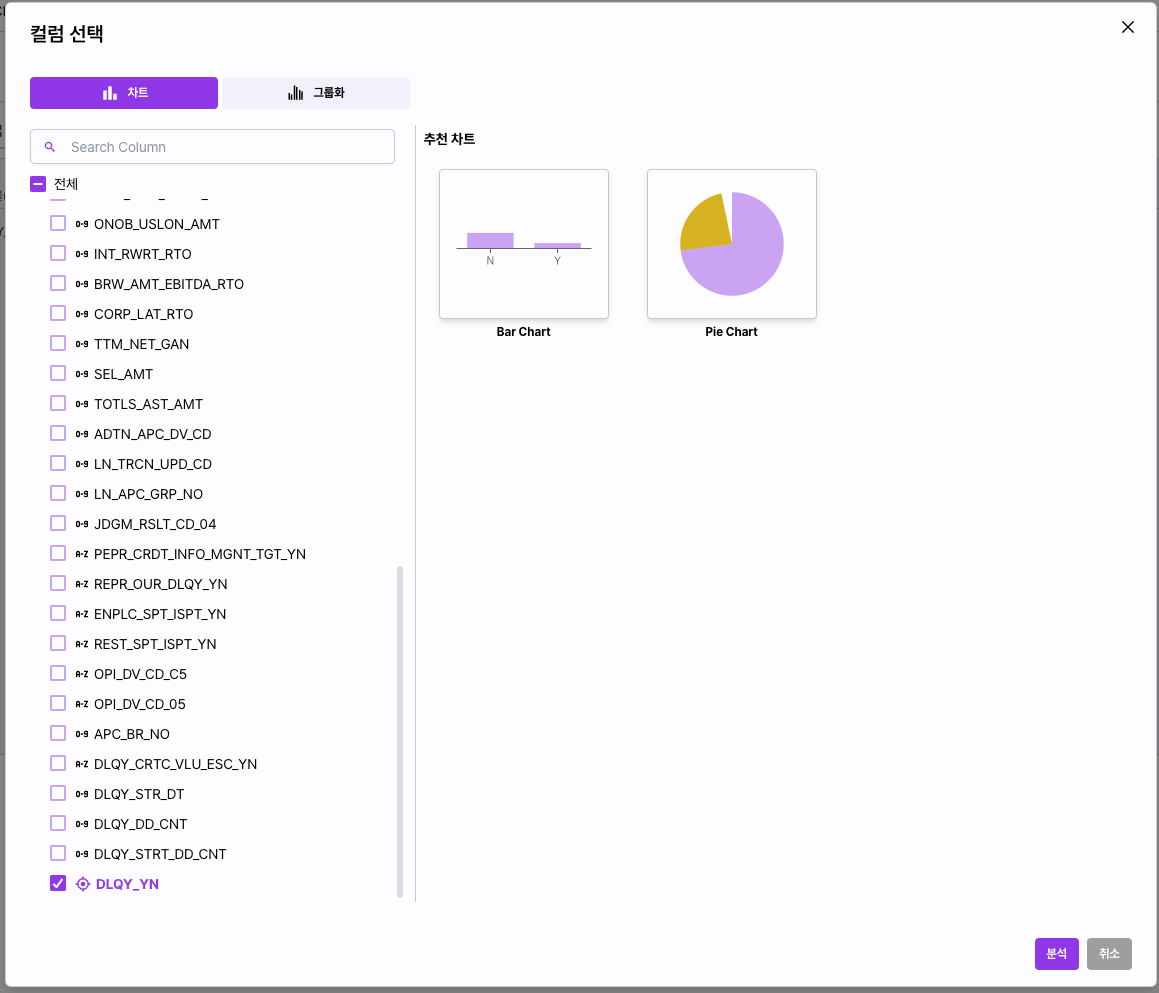
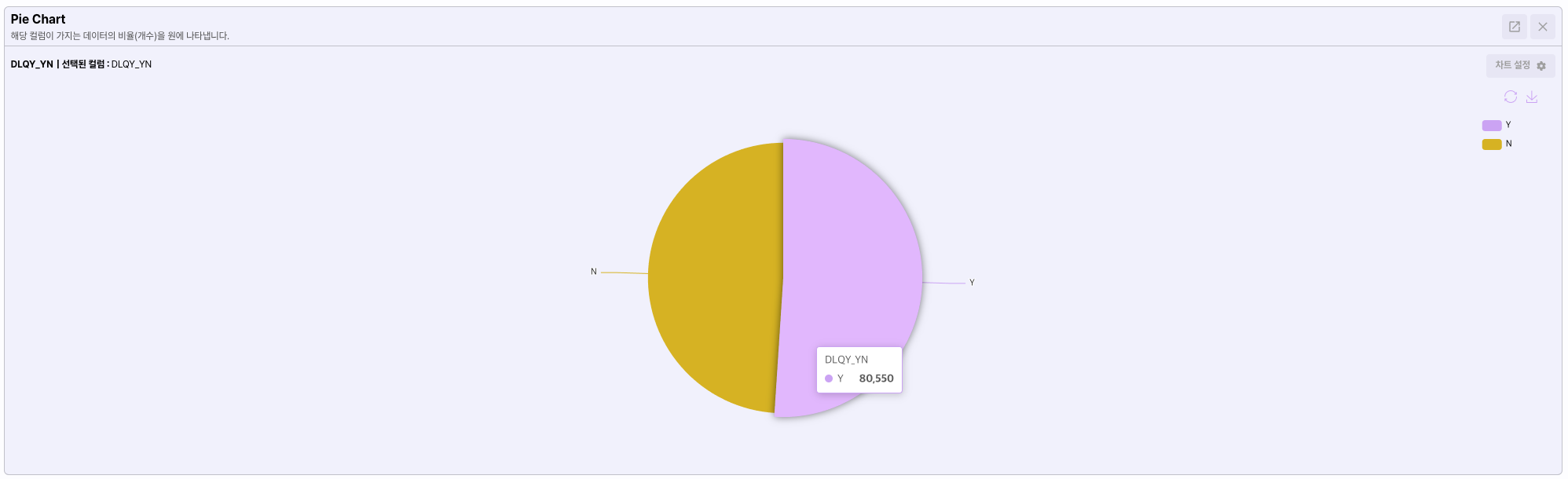
분석의 목표인 DLQY_YN컬럼을 선택하고 파이차트를 선택 합니다.
[분석] 버튼을 클릭해 차트를 생성 합니다.
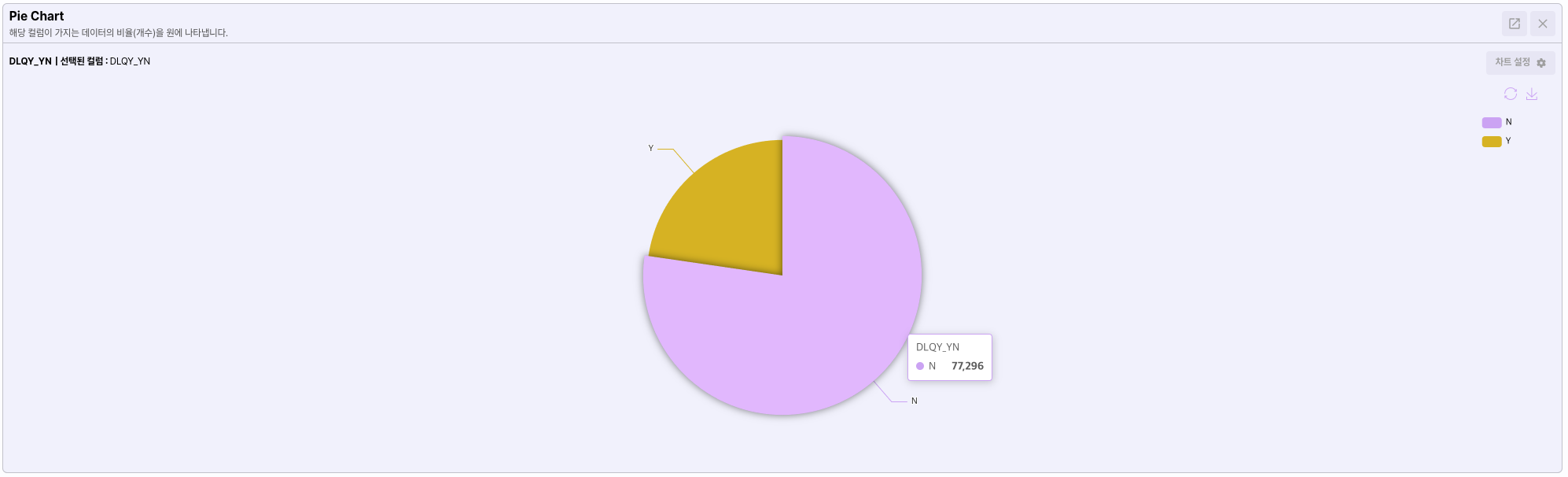
타겟 데이터를 시각적으로 분석해본 결과 인공지능 모델을 만들기에 비율이 적절하지 않은것을 확인 할 수 있습니다.
Auto 클래스 발란스 기능을 통해 클래스를 고르게 만들어 줍니다.
Class Balancer
상단의 [Action] 버튼을 클릭하고 하위 메뉴에서 [Class Balance] 를 클릭합니다.
불균형한 클래스 (타겟 컬럼)의 수를 맞추는 작업을 자동으로 진행합니다.
그림과 같이 제일 작은 클래스의 개수로 데이터를 자르는 Under Sample과 제일 수량이 많은 클래스의 숫자와 동일하게 데이터를 증식시키는 Over Sample,
마지막으로 원본 데이터로 변경하는 Original이 있습니다.
원하는 Sample 기법을 선택하고 Save를 클릭하면 잠시 후 데이터가 변경됩니다.
Over Sample을 선택하고 [저장] 버튼을 누릅니다.
잠시 뒤 컬럼정보를 확인해 보면 DLQY_YNe데이터가 100,000건에서 157,846건으로 늘어난것을 확인 할 수 있습니다.
다시한번 Analysis 탭에서 같은 방식으로 파이차트를 생성해 보면 그림과 같이 데이터의 비율이 동일하게 맞춰진것을 확인 할 수 있습니다.